Diffusion Model results on pre-trained VQVAE latents of NFBS MRI Dataset: Week 6 & Week 7#
What I did this week#
My current code for VQVAE & DM is well tested on MNIST dataset as shown in the previous blog posts. I extended the current codebase for MRI dataset by using 3D convolutions instead of 2D ones, which resulted in 600k parameters for VQVAE for a downsampling factor f=3. I used a preprocess function to transform MRI volumes to the desired shape (128,128,128,1) through DIPY’s reslice and scipy’s affine_transform functions, followed by MinMax normalization. I trained the VQVAE architecture for batch_size=10, Adam optimizer’s lr=2e-4, 100 epochs. I followed suit for downsampling factor f=2 as well and got the following training curves-
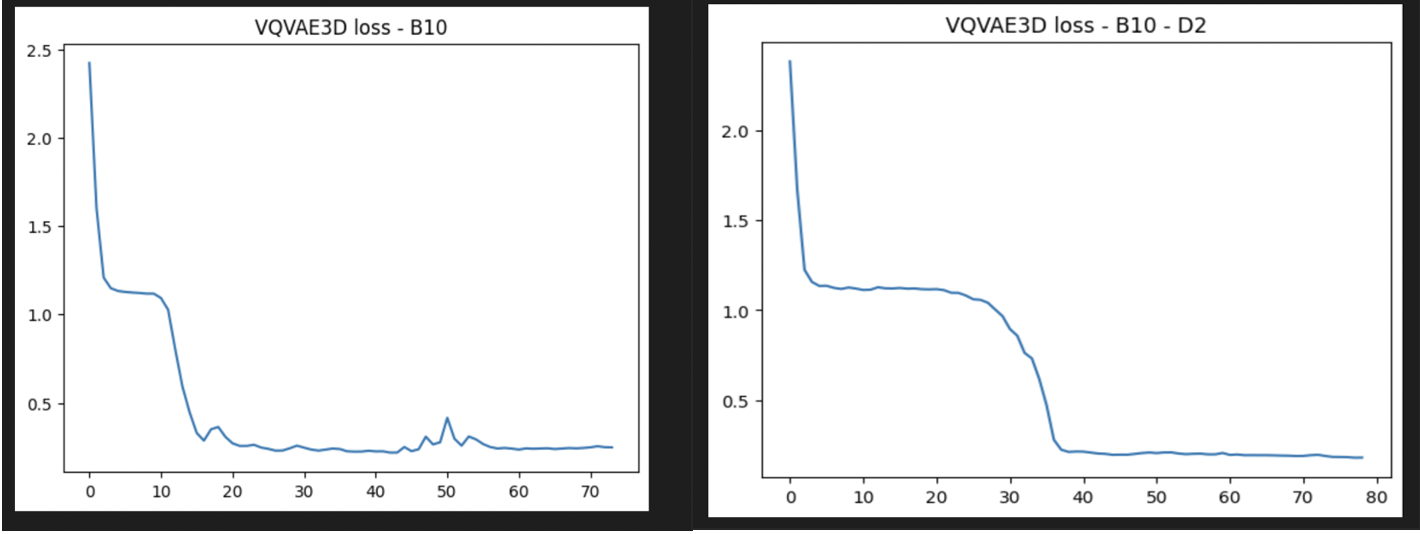
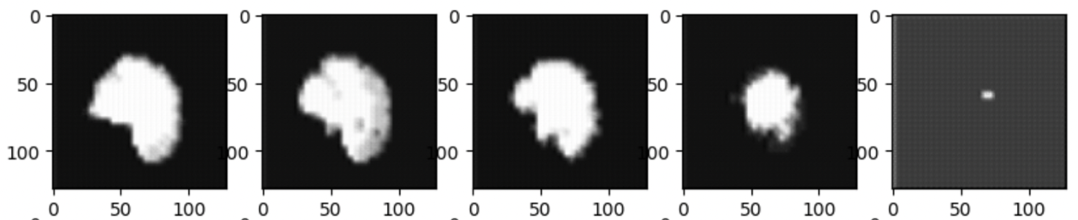
The reconstructed brain volumes on the test dataset on the best performing model are as shown below. As seen in the first image, there are black artifacts in the captured blurry brain structure. Whereas the second image(f=2) does a better job in producing less blurrier brain structure. Nonetheless we only see the outline of the brain being captured with no micro-structural information inside them.

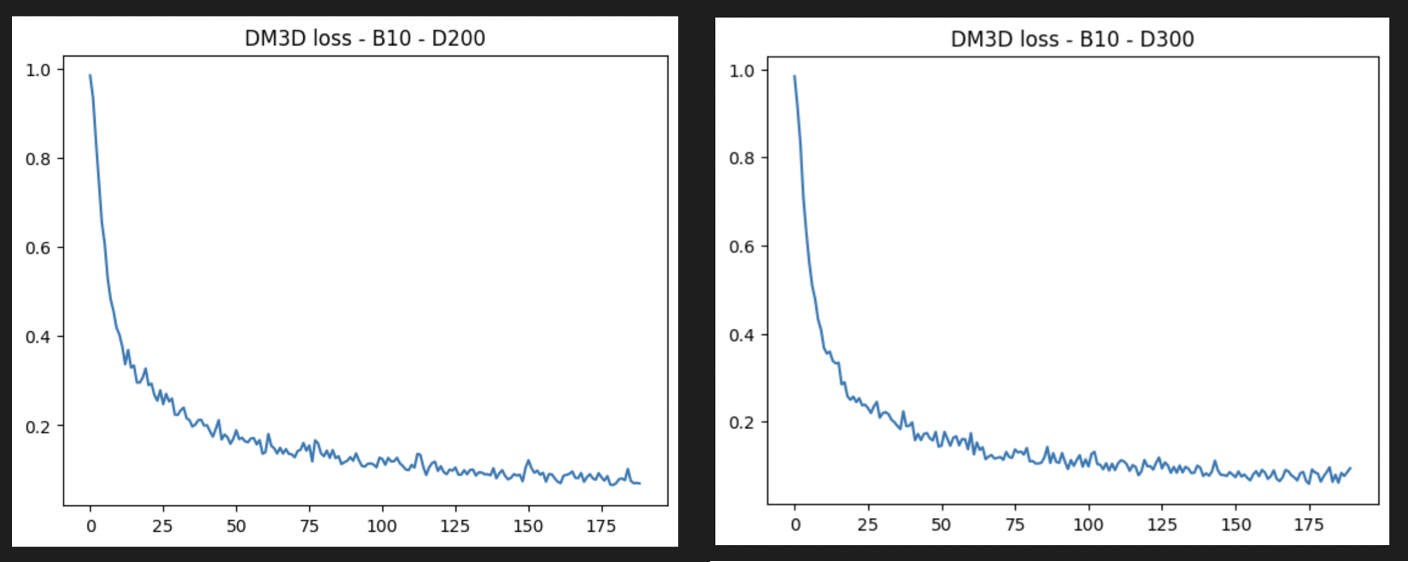
Later, the 3D Diffusion Model was trained for approximately 200 epochs for 200 & 300 diffusion time steps in two different experiments respectively. The training curves and obtained generations are shown respectively. Both the generations are noisy and don’t really have a convincing outlook.

Given the achieved noisy generations, I decided to train VQVAE for a higher number of epochs. This may also indicate that the performance of DM is hitched on good latent representations i.e., a trained encoder capable of perfect reconstructions. So I trained f=3 VQVAE for a higher number of epochs as shown below.
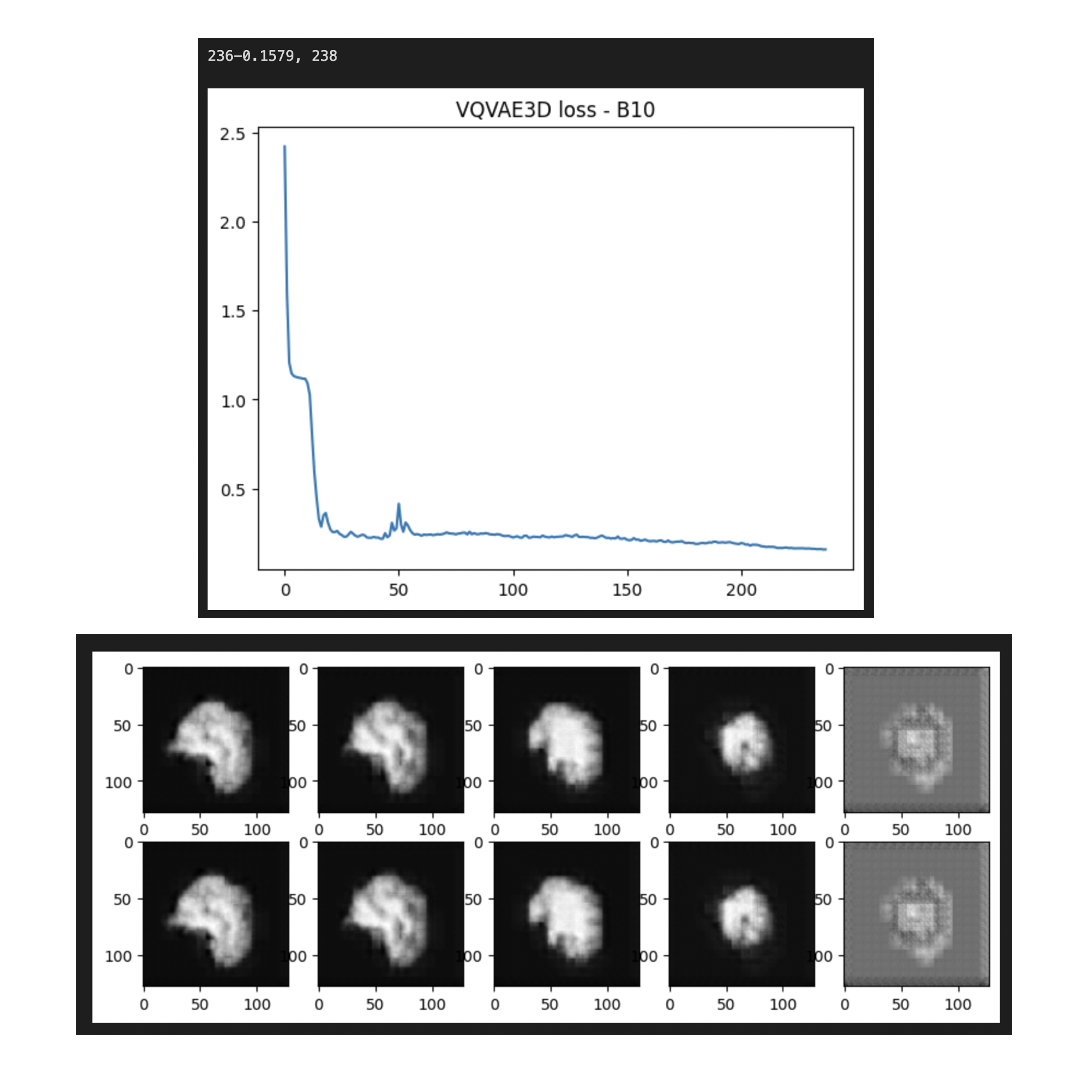
The reconstructions obtained on best VQVAE seemed to have produced a better volumetric brain structure. Although, a common theme between all reconstructions is that we see a pixelated output for the last few slices with a checkerboard sort of artifacts. Anyhow, I ran a couple more experiments with a more complex VQVAE model that has residual blocks to carry forward information. None of the reconstructions nor the DM generations have made any progress qualitatively.
What Is coming up next week#
One idea can be working to improve VQVAE’s effectiveness by playing around with architecture components and hyper-parameter tuning. Alongside I can also work on looking into checkerboard artifacts seen in the reconstructions.