Week 9 into GSoC 2024: The Conditional VAE implementation#
What I did this week#
This week was a bit shorter than usual because Thursday was a holiday in the Basque Country, and today we had an outdoor activity with my lab mates (we went kayaking to the Urdaibai Biosphere Reserve). Nevertheless, it was full of advances and interesting scientific matters.
As I mentioned in my last blog post, this week I worked on the implementation of the conditional VAE based on this implementation .
As a refresher, the main idea behind conditional generative models is being able to generate new data with some desired properties or parameters. To achieve this, it is common to organize the latent representation in a way that allows locating the regions in which the desired properties are found.
For example, imagine our VAE learned a latent representation of images of cats with different fur lengths. If we do not condition our latent space on the fur length, our model might not learn about this distinctive feature found in the data space, and cats with drastically different fur lengths may be closely clustered together in the latent space. But with conditioning, we can tell the model to cluster the images along a “fur-length” dimension, so if we sample 2 images from a line that varies along that dimension but in opposite sides, we get a cat with very short fur, and another one, with very long fur. This results in a generative process that can be tuned on demand!
However, there are many methods to condition a Variational AutoEncoder, and they usually depend on the type of variable we want to condition on, so the methods for categoric variables (cat vs. dog, bundle_1_fiber vs. bundle_2_fiber, etc.) and continuous ones (age of the person, length of a streamline) are normally not applicable to both types.
In the case of the FiberCup dataset, I chose to condition the latent space on the length of the streamlines, which is a continuous variable and it is a fairly easy thing to learn from the morphology of the streamlines.
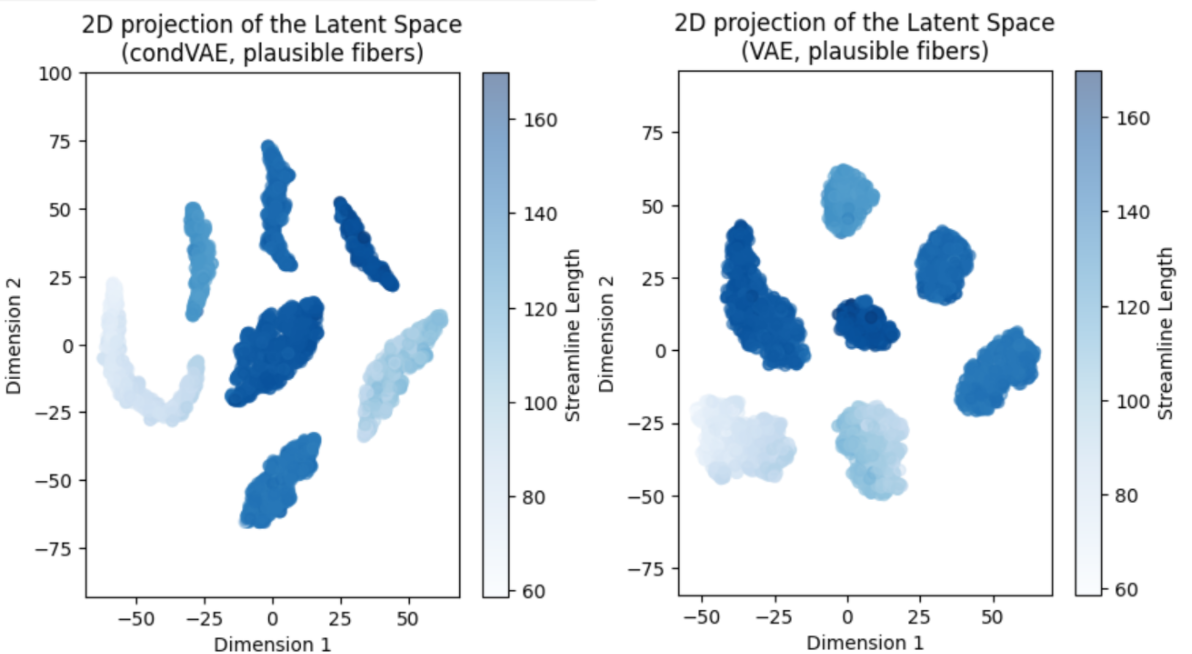
After implementing the conditional VAE as in the provided reference and training it for 64 epochs (early stopped due to lack of improvement in the MSE) I did not get a decent reconstruction, but the latent space seems to be organized differently compared to the vanilla VAE, which suggests that the conditioning is doing something (good or not, we will see…).

On the other hand, note that the FiberCup has 7 distinct bundles, and both latent spaces show (when 2D-projected with the t-SNE algorithm) 7 clusters, suggesting that the network does know about the different bundles. Samples/streamlines are colored according to their length, and even if the bundle to which they belong is not plotted, we know that each cluster is formed by streamlines of different bundles because each bundle has a distinctive length.
Note that the t-SNE representation may have aligned other dimensions more meaningful to the algorithm that do not necessarily include the conditioning variable (streamline length). Maybe the authors of the code I based mine were lucky to get the alignment, or smart enough to manipulate the conditioning variable (normalization, Z-scoring, etc.) to make t-SNE grab this information and put it along an axis in their plots.
What is coming up next week#
After discussing with my mentors, we decided to take two steps:
- Validate reliably whether the conditioning is working or not. For this, there are two strategies:
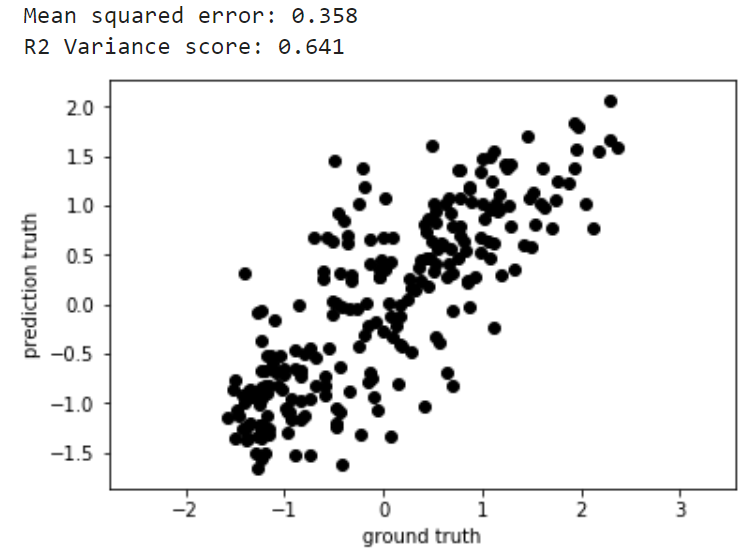
Checking that the predicted conditioning variable matches the input. In other words, measuring the MSE between the “true age” VS the “predicted age”, their correlation, and plotting one against the other. This way you know how good the encoder is capturing the conditioning variable variation in the training data. The authors of the paper I based my implementation on do it like this:
Visual checking fiber generation for specific bundles. Knowing that different bundles have different fiber lengths, we try to generate fibers of specific length, and see whether the generated fibers belong to the desired bundle (no matter if they are plausible or implausible). Having length as the conditioning variable allows us to perform this trick, what would not be so intuitive to check if we had used Fractional Anisotropy or other DTI-derived metrics, as these are not visually as intuitive as length.
To try out an adversarial framework, which is 1) easier to implement 2) easier to understand, and 3) likely to also work (we’ll see if better or not). The idea is to have a discriminator that tries to predict the conditioning variable from the latent space, and the encoder tries to fool the discriminator. This way, the encoder learns to encode the conditioning variable in the latent space, and the discriminator learns to predict it. This is a very common approach in GANs, and it is called “Conditional GAN” (cGAN). As a result, we would have what I would call a conditional adversarial VAE (CA-VAE). You can read more about adversarial VAEs in this work or in this one.
Did I get stuck anywhere#
Luckily this week I also did not get stuck in any problem, but I am a bit worried about the quality of the reconstructions of the cVAE. I hope that the adversarial framework will help with this.
Until next week!