Week 11 into GSoC 2024: The Adversarial AutoEncoder#
What I did this week#
This week was all about learning about adversarial networks, attribute-based latent space regularization in AutoEncoders, and fighting with Keras and TensorFlow to implement the adversarial framework. It was a bit (or two) challenging, but I managed to do it, thanks to a very nice and clean implementation I found, based on the original adversarial AutoEncoders paper.
I still did not implement the attribute-based regularization (AR), but once I train the adversarial AutoEncoder (AAE from now on), visualize its latent space, and check that I can generate samples from a specific class (bundles in our case), I will implement it. Hopefully, all this will go smoothly. For now, I succeeded instantiating the model without any errors, and next week I will train it.
Anyways, in the figure below you can see the architecture I proposed for the AAE, which should allow conditioning the data generation process on a categorical variable and a continuous attribute:
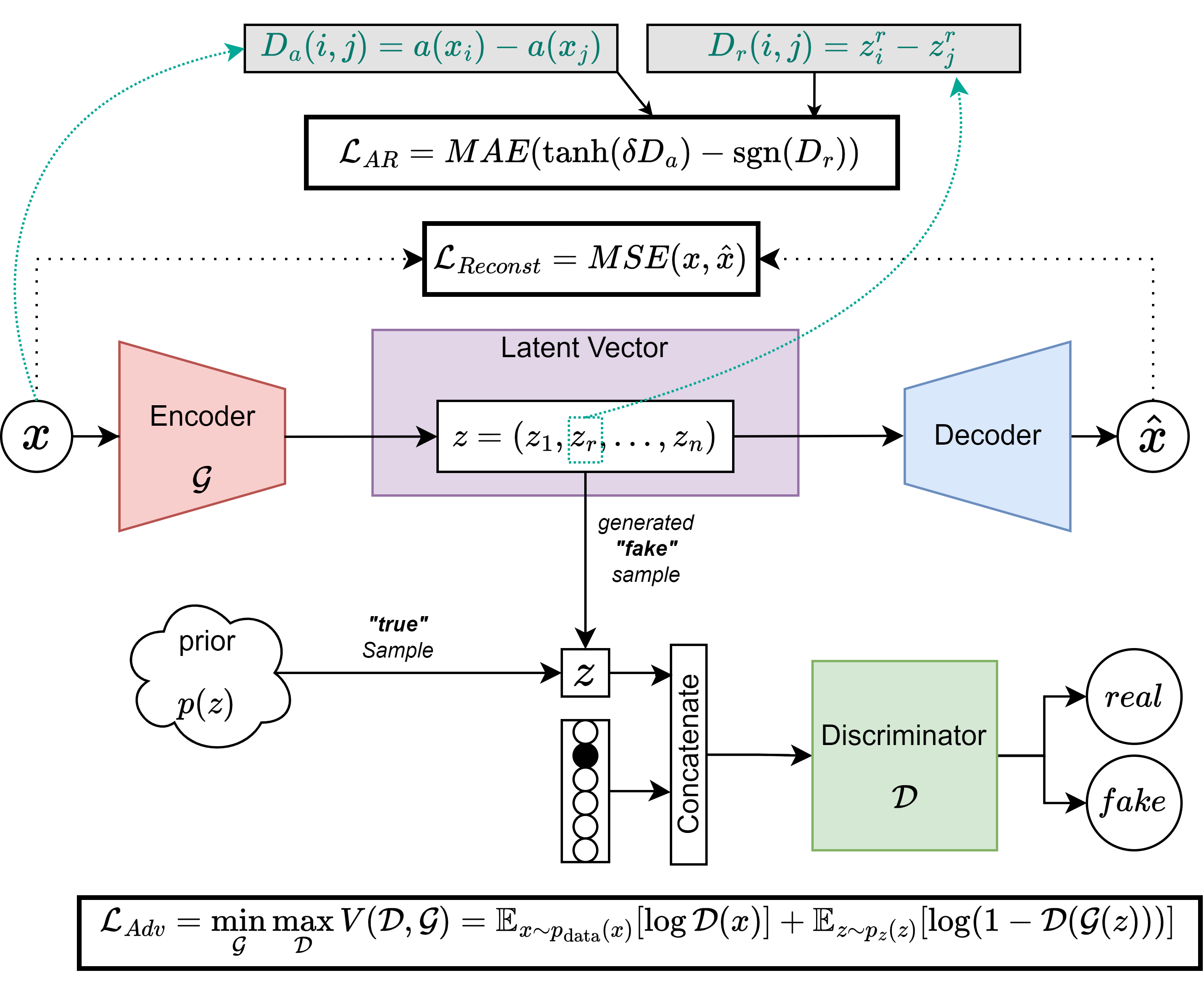
Let’s break down how the AAE works. For those not familiar with how generative adversarial networks (GANs) work, the idea is to have two networks, a generator and a discriminator, that play a game. The generator tries to generate samples that look like the real data (e.g.: pictures of animals), while the discriminator tries to distinguish between real and generated samples. The generator is trained to fool the discriminator, and the discriminator is trained to not be fooled. This way, the generator learns to generate samples that look like the real data (e.g.: real pictures of animals). The adversarial loss (\(\mathcal{L}_{adv}\)) is computed as it is shown in the lowest rectangle.
In our case, the generator is the encoder \(\mathcal{G}\), which generates a latent representation of the input data, which the discriminator \(\mathcal{D}\) tries to distinguish from “real” latent representations, sampled from a given prior distribution. The trick to condition the model on a categorical variable (e.g.: the kind of animal to which the photo belongs to) is to concatenate the latent representation generated by the encoder \(\mathcal{G}\) with the one-hot encoded animal type class. This way, the decoder \(\mathcal{D}\) can generate samples conditioned on a categorical variable. The reconstruction loss (\(\mathcal{L}_{MSE}\)) is computed as it is shown in the middle rectangle, and it ensures that the samples are reconstructed from the latent representation as close as possible to the original data.
As for the AR, we try to tie a continuous attribute of choice found in the data space (e.g.:fur length) to a specific dimension of the latent space. To do this, we compute an attribute-distance matrix in the data space \(D_a\), and we compute a distance matrix from the chosen dimension of the latent space (\(D_r\)). By minimizing the mean absolute error (MAE) between the two matrices, we force the latent space to be organized in such a way that the chosen dimension is related to the chosen attribute. This way, we can generate samples conditioned on the attribute of choice, e.g.: we can generate a specific category (cat) with a specific attribute (fur length). The AR loss (\(\mathcal{L}_{AR}\)) is computed as it is shown in the top rectangle. Coming back to the real domain of our problem, the categorical variable would be the bundle to which the fiber belongs, and the continuous attribute would be the streamline length, and in the future this last one would be the age of the tractogram.
Lastly, I also started writing my last post for GSoC 2024, which will be a summary of the project, the results, and the future work. I will open a draft PR for continuing my work outside of the coding period because I want to keep working on this project as it is a very interesting topic in line with my PhD research.
What is coming up next week#
Next week I will:
Train the AAE. I will probably need to do this in a computing cluster, as my mighty laptop is not powerful enough to train the model in a reasonable time.
Continue writing the final GSoC2024 post.
Open the draft PR to include in the final post and have a tangible place to publish my work as a PR.
Did I get stuck anywhere#
This week I fought a lot with Keras and TensorFlow but as I had gained experience from previous “fights” I managed to not get really stuck, so I am happy to say that I also won this time!
Until next week!