Week 6 into GSoC 2024: Stuck with the Variational AutoEncoder, problems with Keras#
What I did this week#
This week was all about the Variational AutoEncoder. My mentors advised me to drop the TensorFlow implementation of the regression VAE I found last week, to instead directly integrate the variational and conditional characteristics in my AE implementation, following a more modular approach. This was a good decision, as adapting third party code to one’s needs is often a bit of a mess (it already started being a mess, so yeah). Also, once the variational part is done, implementing the conditional should not be that hard.
To provide a bit of intuition behind the VAE, let me illustrate first the “vanilla” AE. This is a neural network that compresses the input data into a reduced representation, and then tries to reconstruct the original data from this representation. We refer to “latent space” to the place where the compressed data representations live. So, once the AE is good at compressing data to the latent space, we could take a sample from it and generate new data.
The objective of the AE is to minimize the difference between the input data and the generated data, also called the “reconstruction loss”.
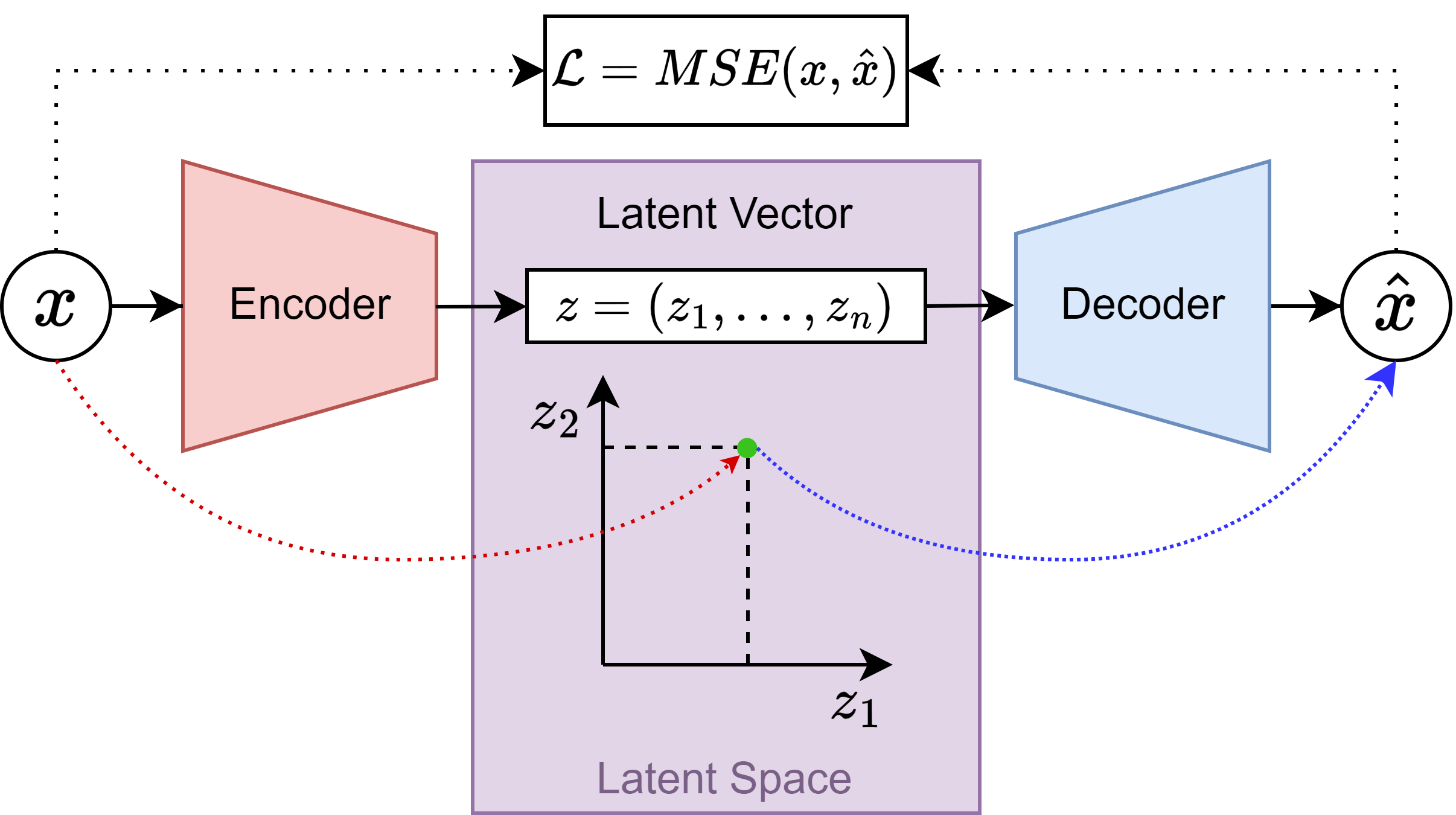
Usually the problem with AEs is that the latent space is full of “holes”, i.e. it is a set of points, meaning that if a sample is taken between two already encoded samples, the generated data will not be an interpolation between the two samples, but a random sample. To solve this, the VAE seeks to “regularize” the latent space, encoding/compressing the input data into distributions that live in it, instead of single points. This way, the latent space is continuous and the interpolation between two samples is meaningful and more likely to follow the data distribution.
The VAE does this by adding a “regularization loss” to the AE, which is the Kullback-Leibler divergence between the latent space distribution and a prior distribution (usually a normal distribution). If you are curious, you can find a nice explanation about the differences between AEs and VAEs here.
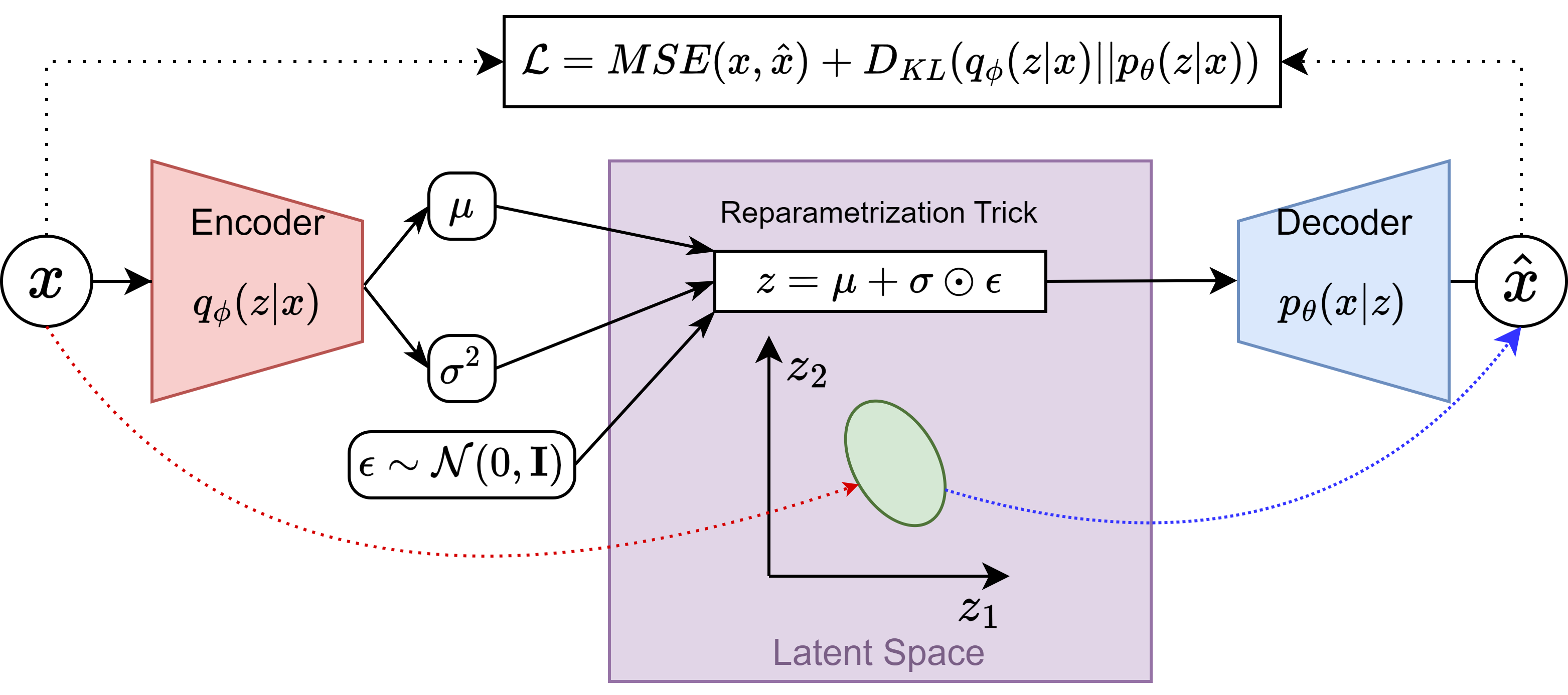
Thus, I started by implementing the VAE in Keras, and I must say that it was not as easy as I thought it would be. I used this VAE example from Keras, adding a ReparametrizationTrickSampling layer between the Encoder and the Decoder.
The main problem was that the Keras implementation was not behaving as expected because it was giving me problems of model initialization, so I encapsulated the Encoder and the Decoder parts into individual keras.Model class instances, to put them all together under a wrapping Model. Doing this was a bit painful, but it worked.
The problem was that I was not being able to train the model because the loss was constantly nan values.
What is coming up next week#
Next week I must correct the nan problem when training because I am not sure what is causing it. I am using exponential operations in the KL loss computation and in the ReparametrizationTrickSampling layer, which could return excessively large values if the exponent value is too big, leading to an exploding gradients issue. I will explore this.
Did I get stuck anywhere#
I got stuck in the Keras implementation of the VAE to instantiate the model, but I think I am on the right track now.
Until next week!